Provably V2 is now live and available for anyone to use.
Last year, we introduced Provably V2 and QEDB with a focus on the new protocol and the cryptographic foundations behind verifiable databases. At the time, the product was still in private beta. Since then, we have optimized the system, tested it with multiple clients, improved performance across the stack, and shaped the product around how teams actually want to query and verify data.
At its core, Provably V2 lets data owners preprocess their data once, then serve SQL queries with cryptographic proofs that the answers are correct and complete. In plain English, that means you can query data and verify the result without having to blindly trust the remote system returning it. This is especially useful for distributed systems and emerging AI workloads.
A Successful Private Beta
Verifiable databases are a new primitive, and during private beta we saw some fascinating use cases emerge in the hands of blockchain and AI teams.
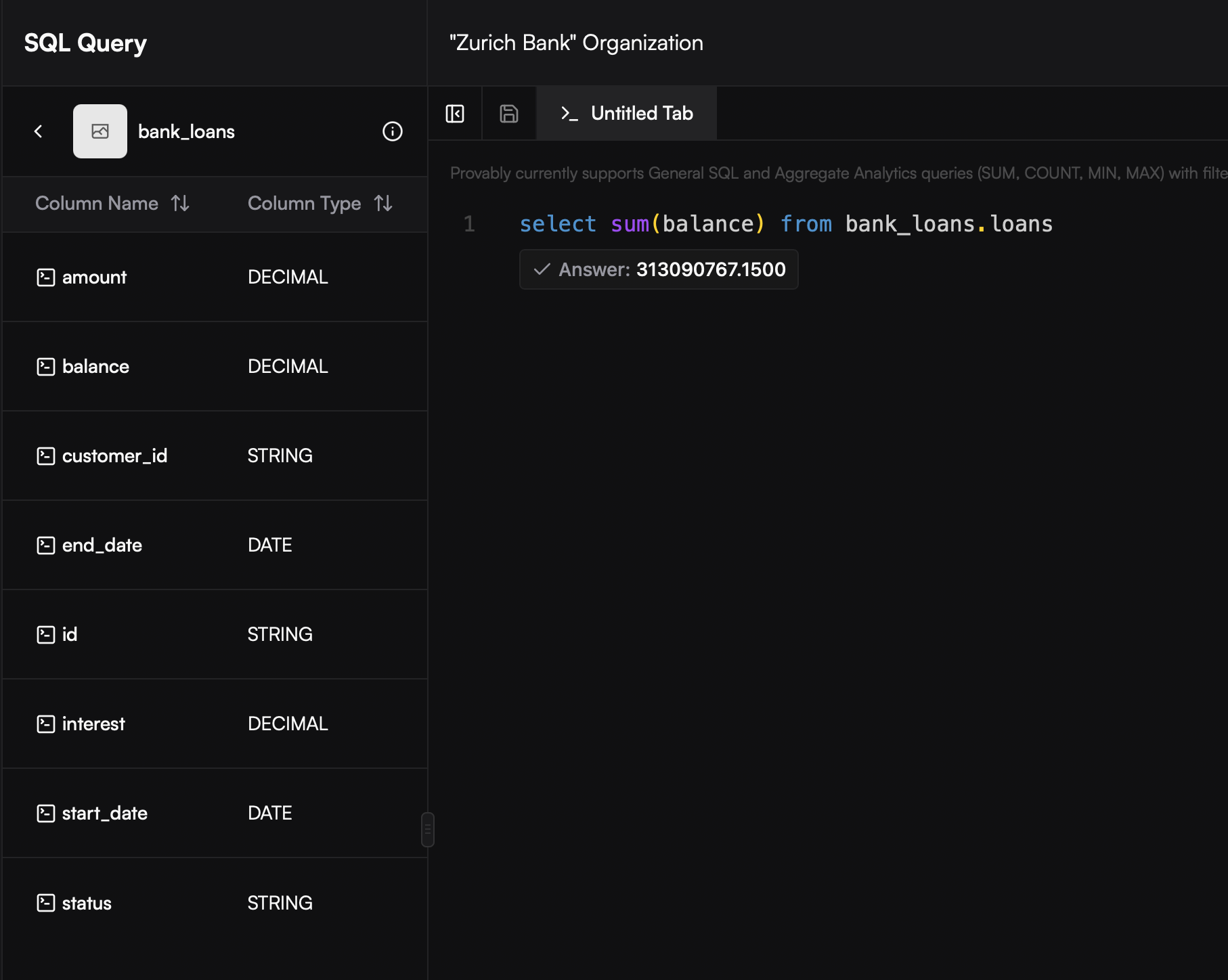
One powerful use case is Private Data Oracles for payments, lending, and compliance. These are especially easy to implement when the underlying data comes from a verifiable issuer, a trusted data provider such as a bank, or transactions on a privacy centric blockchain.
Another strong use case is data markets, where multiple parties collaborate so their AI models can access high quality, fresh data. We see a world where data owners can bolt on Provably and x402 payments in minutes, making their data discoverable and queryable just as quickly.
AI data pipeline integrity is becoming a major challenge as more agents hand off data to one another within and across organizational boundaries. Today, developers are trying to verify the correctness and authenticity of these data flows using logging, observability, and evaluator LLM tooling. During private beta, we also saw early experimentation showing that Verifiable Databases can bring deterministic outcomes to these workflows quickly and efficiently.