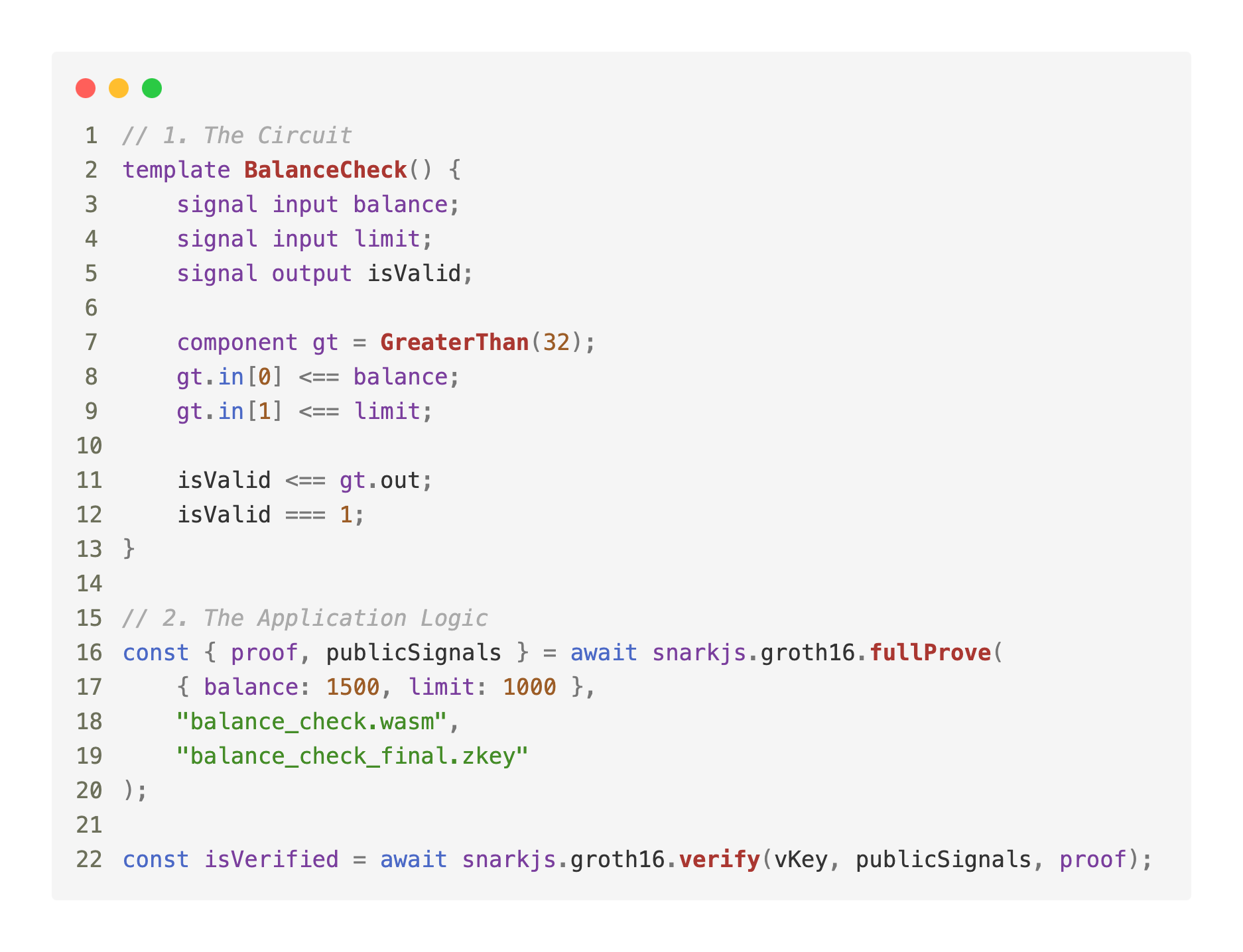
In the world of Zero-Knowledge (ZK), the "Circuit" has been the foundational abstraction for years. The industry standard has been clear: if you want to prove a statement is true, you translate your logic into a set of mathematical constraints.
But for developers building data-intensive applications, this creates a massive headache. Modern software is designed to be flexible and to evolve over time. We write code that changes, branches, and evolves as requirements grow. Databases follow a similar pattern: they allow teams to modify schemas, update data models, or change queries in seconds. This flexibility is a core assumption of how modern applications are built and maintained.
The "Circuit" model, by contrast, relies on rigidity. Using it feels less like writing software and more like designing hardware. You have to pre-calculate every "wire" and "gate" before you’ve even processed a single row of data.
Mapping a dynamic database onto a rigid circuit model makes development complex and inflexible; development speed just slows down, like hitting a wall.
The Hardcoded Wall
The "Circuit" model operates by transforming logical statements into a static system of mathematical equations. In this paradigm, every potential path of a query must be defined upfront, creating a fixed structure where inputs and outputs are determined the moment the circuit is compiled.
Because the proof depends on the specific mathematical structure of the circuit, the system remains locked to the requirements defined at the moment of creation. The logic is effectively frozen into the architecture. When a data model evolves or a query requires a new filter, the static circuit can no longer accommodate the change.