TLDR: Major teams are building confidential AI infrastructure to store and process sensitive workloads. TEEs, confidential compute, and verifiable logs can produce millions of rows of attestations and data per user.
The real challenge is this: how do you resolve disputes, run audits, and answer questions in the middle of a crisis quickly and clearly enough to retain user trust?
—--------------
Recently there has been acceleration toward confidential AI infrastructure for enterprise, government, regulated industries, and soon end user data.
Teams like Google Project Oak, Apple’s Private Cloud Compute, OpenAI, Phala, Brave and Telegram’s Cacoon AI have all converged on a similar view: device-side compute is not enough, and server-side confidential compute will be necessary.
This trend is interesting to me because I have spent time with privacy chains and wallet infrastructure providers that need to prove the integrity of their data to someone else. Think of real world audits and queries in the middle of a crisis situation.
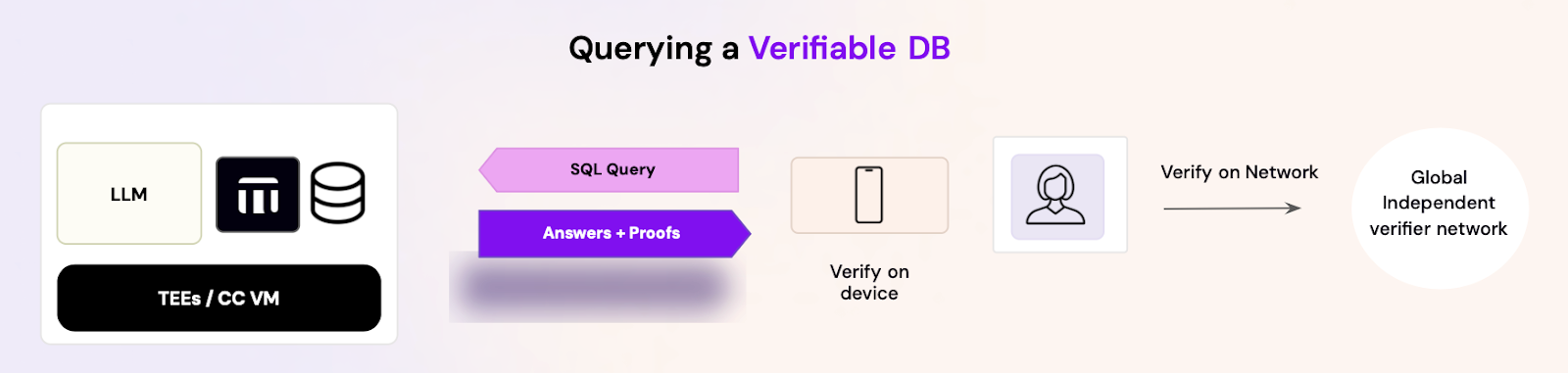
A takeaway from these conversations is that confidential computing stacks, blockchains, and verifiable logs all play a similar role. They capture, with integrity, the state of the infrastructure, the models or applications that are running. Verifiable logs capture events in data pipelines, data access and policy changes.
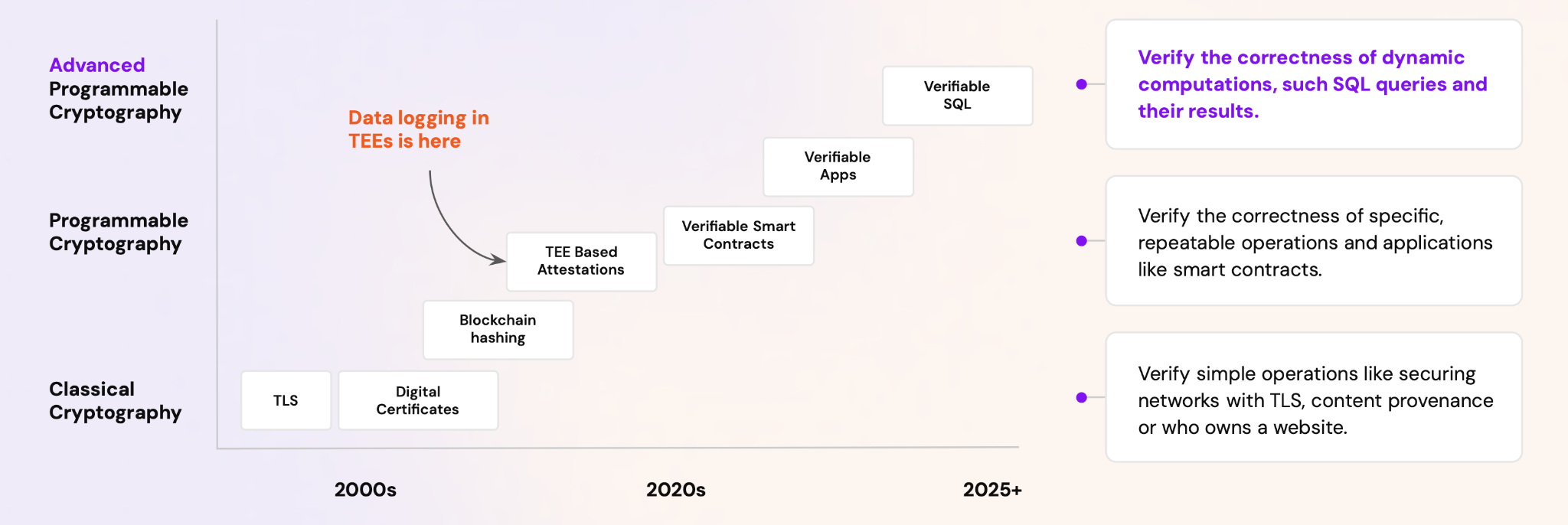
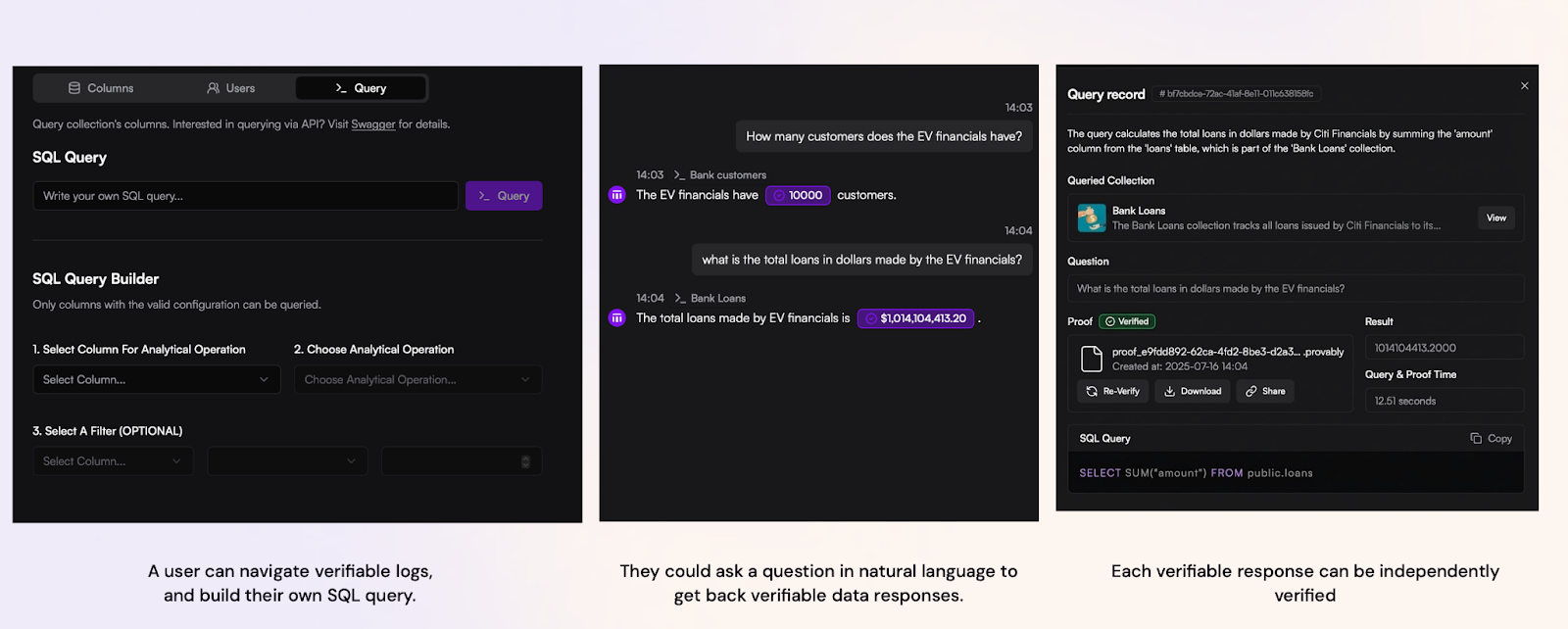
The hard part starts after you have built this beautiful confidential stack. As an engineer you might be proud of the system, but how do you prove this to millions of users and to auditors in a way they can actually use?